
1.复数
我们把形如z=a+bj(a,b均为实数)的数称为复数,其中a称为实部,b称为虚部,j称为虚数单位。
一个复数时一对有序浮点数 (x,y),其中 x 是实数部分,y 是虚数部分。
Python 语言中有关复数的概念:
1、虚数不能单独存在,它们总是和一个值为 0.0 的实数部分一起构成一个复数
2、复数由实数部分和虚数部分构成
3、表示复数的语法:real+imagej
4、实数部分和虚数部分都是浮点数
5、虚数部分必须有后缀j或J
2.and,or
(有0,逻辑数据时进行c/c++中的&&与运算(1,0),or取前and取后)
10 and 20 -> 20
10 or 20 -> 10
10 & 20 -> 0 (01010&10100=00000)每位进行与运算
10 | 20 ->30
逻辑数据,是一种操作数类型。是用来表示二值逻辑中的 "是"与 “否” 、或称 "真"与 “假” 两个状态的数据。
3.Python浮点数占4个字节
4.pass 表示空语句
5.encode异常报错
-> AttributeError: module ‘sys’ has no attribute 'setdefaultencoding
Python3字符串默认编码unicode, 所以sys.setdefaultencoding也不存在了,所以去掉,sys.setdefaultencoding
-> UnicodeDecodeError: ‘ascii’ codec can’t decode byte ……
默认执行的decode(‘ascii’)执行为decode(‘utf-8’)
1 | import sys |
-> ‘gb18030’ codec can’t decode byte 0x80 in position 10: incomplete multibyte sequence(解决方法)
出现这种报错的问题原因是:我们要解码的数据不符合我们期望的类型,所以有时候我们知道数据的编码格式,但是其中有一些其他格式的数据,这样我们就要将其他的格式数据进行忽略,否则解码会报错,程序运行不下去,在decode 中添加’ignore’参数即可
data_str = **
data.decode(‘gb18030’,’ignore’).encode(‘utf8’)
读取文件的时候也可以使用ignore
1 | file = open(path, encoding=’gb18030’, errors=’ignore’) |
-> 真正解决Windows下UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xff in position 0错误的方法
在open函数encoding参数中设置正确的文件编码。
1 |
|
6.CSV读取大文件报错
-> _csv.Error: field larger than field limit
该问题出现在用csv读取文件的时候,出现大字段,导致超过字段默认限制,而无法读取。
因此,需要在使用csv读取文件前,先设置下csv字段显示大小。
1 | csv.field_size_limit(500 * 1024 * 1024) |
7.判断key是否存在
方法一:使用自带函数实现 print(dict.contains(“b”))
方法二:使用in方法 ‘a’ in d /d.key()
方法三:dict.get(‘a’,'没有该key‘)避免了dict[‘a’]没有就报错
- 判断字典key的个数: len(dict)
8.列表越界报错
-> IndexError: list index out of range 错误原理及解决方法(python)
报错原因:(1)下标超出范围,(2)list是空的,没有一个元素
源文档末尾存在一行空行可以用try…except模块跳过该错误,或删除末尾的空行
9.plt.figure()的使用
1 | figure(num=None, figsize=None, dpi=None, facecolor=None, edgecolor=None, frameon=True) |
- num:图像编号或名称,数字为编号 ,字符串为名称
- figsize:指定figure的宽和高,单位为英寸;
- dpi参数指定绘图对象的分辨率,即每英寸多少个像素,缺省值为80 1英寸等于2.5cm,A4纸是 21*30cm的纸张
- facecolor:背景颜色
- edgecolor:边框颜色
- frameon:是否显示边框
10.Python 读写 tsv
TSV文件和CSV的文件的区别是:
前者使用\t作为分隔符,后者使用,作为分隔符
tsv和csv都是以纯文本文件存储的电子表格格式,两者都可以用文本编辑器、Sublime等程序打开,同时他们又是电子表格形式,可以用Excel等电子表格程序打开。tsv和csv被广泛用于计算机存储简单的电子表格数据(貌似csv用的更频繁些~但是有些老外喜欢用tsv格式……嗯……坑货!)
1 | #TSV:tab separated values;即“制表符分隔值”,用制表符分隔数据 |
1.python库
1 | #第一步:修改csv包的解析文件模式 |
3.使用pandas:
1 | #使用pandas读取tsv文件 |
11.pyplot绘制的图中中文不会正常显示
-> RuntimeWarning: Glyph 22270 missing from current font. font.set_text(s, 0, flags=flags)
1 | 解决办法: |
12.1e6 = 1000000
13.深浅拷贝

14.缓存机制

15.切片的原理
16.Python取整

17.可视化图简介
-
直方图
-
箱线图
-
小提琴图
-
条形图
-
堆叠柱状图
-
气泡图
-
饼状图
-
热力图
18.os.path.exists()
os即operating system(操作系统),Python 的 os 模块封装了常见的文件和目录操作。
os.path模块主要用于文件的属性获取,exists是“存在”的意思,所以顾名思义,os.path.exists()就是判断括号里的文件是否存在的意思,括号内的可以是文件路径。
存在返回True;如果不存在,返回的则是FALSE。
19.os.mkdir()与os.makedirs()的区别
os.mkdir(path),他的功能是一级一级的创建目录,前提是前面的目录已存在,如果不存在会报异常。当你的目录是根据文件名动态创建的时候,你会发现他虽然繁琐但是很有保障,不会因为你的一时手抖,创建而创建了双层或者多层错误路径
os.makedirs(path),可以一次创建多级目录,哪怕中间目录不存在也能正常的(替你)创建,想想都可怕,万一你中间目录写错一个单词…
20.创建文件和文件夹
-> import os
1 | def mkdir(path): |
1 | #"x" - 创建 - 不存在将创建一个文件,如果文件存在则返回错误 |
-> import csv
1 | with open(filepath,'w') as file: |
21.Matplotlib设置坐标轴
xlim():设置x坐标轴范围ylim():设置y坐标轴范围xlabel():设置x坐标轴名称ylabel():设置y坐标轴名称xticks():设置x轴刻度yticks():设置y轴刻度
22.plt.scatter()的使用 1,2
1 | scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, verts=None, edgecolors=None, , data=None, *kwargs) |
x, y : 相同长度的数组,数组大小(n,),也就是绘制散点图的数据;
s:绘制点的大小,可以是实数或大小为(n,)的数组, 可选的参数 ;
c:绘制点颜色, 默认是蓝色’b’ , 可选的参数 ;
marker:表示的是标记的样式,默认的是’o’ , 可选的参数 ;
cmap:当c是一个浮点数数组的时候才使用, 可选的参数 ;
norm:将数据亮度转化到0-1之间,只有c是一个浮点数的数组的时候才使用, 可选的参数 ;
vmin , vmax:实数,当norm存在的时候忽略。用来进行亮度数据的归一化 , 可选的参数 ;
alpha:散点的透明度,实数,0-1之间, 可选的参数 ;
linewidths:散点的边缘线宽 ;
edgecolors:散点的边缘颜色;
23.生成1到100的列表并打印的方法
1 | #使用list生成 |
24.numpy.random.randn()的使用
numpy.random.rand(d0,d1,…,dn)
- rand函数根据给定维度生成[0,1)之间的数据,包含0,不包含1
- dn表格每个维度
- 返回值为指定维度的array
25.plt作图时出现横坐标或者纵坐标乱序的解决方法
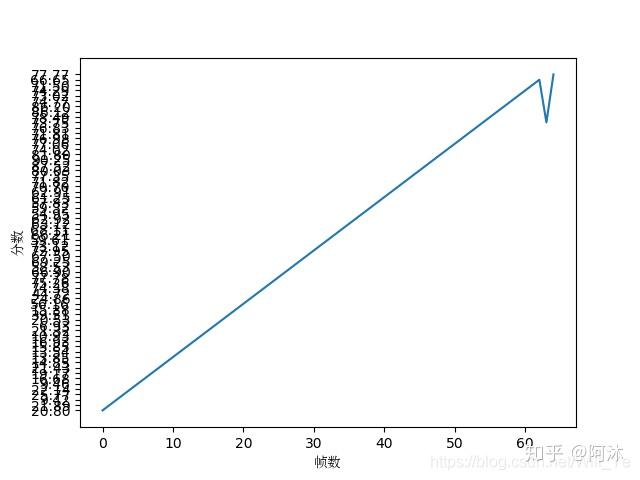
可以看到Y轴坐标已经乱掉了。
出现这种情况的主要原因在于:Y轴的值不是int或float这种数据,而是 string这种类型,导致转换成数据的时候出错。
1 | fig =plt.figure(100) |
1 | #我使用的 |
26.plt.plot()的使用
1 | #不显示y轴,x轴 |
27.在文本中寻找关键词(已知)
28.字符串是否为关键字
1 2
29.创建关键词
30.502 Bad Gateway
出现502的原因是:对用户访问请求的响应超时造成的
解决办法:
1.提高 Web 服务器的响应速度,也即减少内部的调用关系,可以把需要的页面、素材或数据,缓存在内存中,可以是专门的缓存服务器 ,也可以Web服务器自身的缓存,提高响应速度;
2.网络带宽的问题,则对传输的数据包进行压缩处理,或者向IDC申请增加带宽;
3.属于内部网络的故障或设置问题,也即内部网络拥塞,可能内部存在大量的数据调用或交互造成的,则需要优化内部网络传输或协议;
4.数据库的数据读取造成前端服务器 ,响应用户的请求变慢,那么必须提高数据库的处理能力,若是只读业务可以增加数据缓存的模式 或者增加数据库备机,分散读压力;
若是写的压力,则可以考虑延迟写的模式,想这个时候做数据写分散肯定来不及
40 求对数


